一.全连接神经网络的弊端
在上章学习完神经网络基础后,几乎所有问题的输入都能够Resize处理一下后扔进全连接神经网络(FNN)中进行训练。在图像学习任务中,图像(多通道)这类(N*C*W*H)多维输入格式数据需要通过Resize展为(N*M)的M维数据送入全连接神经网络,这种做法非常的简单粗暴直接,当然也带来了一些问题:
- 忽视了图像数据的结构信息:直接Resize的做法没有考虑图像数据中的结构信息,因为图象是多维的,存在着结构上的关系。比如图像中一般都存在着颜色过渡,相邻结构之间颜色域应该是相似的,这也是应该被学习的。
- 学习参数非常庞大:一般我们需要训练的图像数据集都非常庞大,比如输入一个RGB格式的500*500的图像(一般分辨率),第一层隐含层神经元有100个,这就需要 3*500*500*100 = 75000000 个训练权重w,然后要达到好的训练效果我们还需要多层并训练多轮,这样效率十分低下!
- 学习域过大:图像都具有自己的特征,每个特征都有自己的学习域。想一下如果我们需要进行图像识别,比如对于大象来说我们一般不需要看到图像全景,只需要看到大象鼻子这一特征就可以基本确定这个图象是一只大象,但是全连接神经网络每次都要去学习全部的图像信息,训练的性价比太低。
二.卷积神经网络结构
基于全连接神经网络的种种弊端,卷积神经网络(CNN)横空出世。卷积神经网络的核心思想在于:我们能不能将传统神经网络在识别图像时变得像人一样灵活,能够用双眼去识别图像的特征从而在大脑中聚合特征信息得到识别结果,而不是盲目的去学习全部?卷积神经网络结构主要由:输入层、卷积层、池化层、激活层、全连接层 组成,我们将分别介绍。

手写数字识别卷积神经网络结构图
1.输入层
卷积神经网络(CNN)输入层的输入格式保留了图片本身的结构,对于C个通道的(H*W)大小的图像输入数据为(C*H*W) 多维格式。当然如果有n个样本,则输入为(n * C * H * W)格式,其中每个数值为图像在该处的像素值大小。比如对于黑白的 28×28的图片,CNN 的输入是一个 1x28×28 的二维神经元;对于 RGB 格式的 28×28 图片,CNN 的输入则是一个3×28×28 的三维神经元。


2.卷积层
卷积层是构建卷积神经网络的核心层,它产生了网络中大部分的计算量。
(1)图像上的卷积运算
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。以下分别是单通道卷积运算和多通道卷积运算的实例。
注意:
- 两个做卷积运算的矩阵通道数必须相同,才能进行对应元素的内积运算。
- 不管原始运算矩阵通道数为多少,最终一次卷积运算结果一定为一个单通道矩阵。


(2)卷积核
在卷积神经网络中,由滤波器filter所组成的权重矩阵就被称为是一个卷积核。卷积核对局部输入数据进行卷积计算,每计算完一个数据窗口内的局部数据后,卷积核不断平移滑动,直到计算完所有数据组成一个特征矩阵。卷积核的空间大小被称为感受野(即卷积核一次可以看到的空间,类似于人眼)。
注意:
- 卷积核中的数值均为权值:卷积核矩阵经过随机初始化后,需要进行训练来确定权重参数。
- 每个卷积核需要与输入数据通道数一致,且计算结果均为单通道特征矩阵。如果本卷积层含有m个卷积核,则输出结果会组成一个m通道的 特征map,继续参与下层训练传递。
- 卷积核一般空间较小,常见的比如3x3,5x5的卷积核。小感受野的卷积核能学习更多的特征,训练效果更好。
- 卷积核运算默认含有bias:即在卷积核运算中其实最终求和后还要加上一个bias偏置量,这个也是训练参数,用于构成线性运算。在代码编写时也可以设置去除bias。


卷积层输出张量尺寸计算公式:
其中:
- O(OutputSize):输出张量尺寸
- I(InputSize):输入张量尺寸
- K(KernalSize):卷积核尺寸
- P(Padding):四周填充数(p=1表示填充一圈,默认填充0)
- S(Stride):卷积核移动步长,默认为1

卷积层的作用:
- 共享权值,减少训练参数:引入卷积核的卷积层后,某个卷积核是对整个输入张量都进行移动和卷积运算的,是整个输入上共享的。原全卷积神经网络的某隐含层参数量为 C*H*W*N,而卷积层的参数量为C*k*k*m,其中k为卷积核大小远小于H/W,m为卷积核数量也远小于神经元数量N,所以参数总量和运算次数将减少很多。
- 保留结构关系信息:通过卷积核在输入张量上的移动,可以保留学习输入数据的结构关系。通俗点来说,每个卷积核就相当于一个特征提取器的“眼睛”,卷积核的大小就是眼睛的感受野。每个卷积核都去学习识别一个特征,但是该特征在图上可能位于任意位置,所以卷积核需要移动遍历整个图像,来学习/寻找/识别这个特征。最后,该层m个卷积核filter的提取结果聚合为一个m维的特征map,继续进行下一层的特征识别与聚合。
3.池化层
当输入经过卷积层时,由于卷积核一般感受视野比较小,步长stride比较小,所以得到的feature map (特征图)还是比较大。所以在卷积层之后一般都通过池化层来进一步压缩减少特征数量,优化训练参数。池化层操作的输出深度还是不变,依然为 feature map 的个数,只改变长宽尺寸大小。
(1)最大池化 Max pooling
池化层类似于卷积核也有一个“池化视野(filter)”,但是池化层不含有训练权重(池化层不需要训练),只提供“池化视野”大小的矩形框。再池化过程中,来对 feature map 矩阵进行移动扫描,对“池化视野”中的矩阵值进行取最大值计算。通俗来说,池化层的作用就是使用一定范围内的最显著(最大)的特征值来代替该范围特征,减少训练参数,又能在一定程度上保留原图像特征结构。

池化可以使得长宽都变为原来的一半,特征变少了
(2)平均池化 Average Pooling
平均池化与最大池化的过程相同,只是计算策略不同。平均池化在移动扫描过程中,对“池化视野”中的矩阵值进行取平均值计算。通俗来说,平均池化的作用就是使用一定范围内的平均特征值来代替该范围特征。
4.激活层
激活层主要对卷积层的输出进行一个非线性映射,因为卷积层的计算本质上还是一种线性计算。常用的激活函数一般为ReLu函数、tanh函数、Leaky ReLU函数等。
5.全连接层
全连接层主要对卷积层提取融合的特征进行重新拟合,减少特征信息的丢失;全连接层在整个卷积神经网络中主要起到"分类器"的作用。将最后一层卷积得到的特征图(矩阵)展开成一维向量,并为分类器提供输入,做好最后目标结果的输出。常用的分类函数比如sigmod(二分类)、softmax(多分类)

6.批标准化层 Batch Normalization
CNN网络在训练的过程中,前一层的参数变化影响着后面层的变化(因为前面层的输出是后面的输入),而且这种影响会随着网络深度的增加而不断放大。机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。但随着输入数据的不断变化,以及网络中参数不断调整,网络的各层输入数据的分布则会不断变化。
BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。Batch Normalization 实现了在神经网络层的中间进行预处理的操作,即在上一层的输入归一化处理后再进入网络的下一层,这样可有效地防止“梯度弥散”,加速网络训练。以下为计算公式和算法流程:
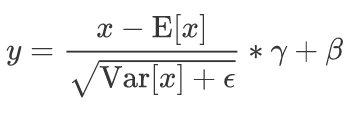

公式含义就是对于所有batch中的同一个channel的元素进行求均值与方差,然后对于所有batch中的每个元素进行减去求取得到的均值,除以方差进行标准化转换,然后乘以gamma加上beta。
后两个参数是为了解决一个问题:变换以后数据是否失去了原本的分布,导致网络表达能力下降?所以为了拟合原本的分布,作者又对每个神经元增加两个调节参数(scale和shift)γ和β,这两个参数是通过训练来学习到的,目的是还原上一层应该学到的数据分布,使得网络表达能力增强。
注意:Batch Normalization 层一般放在每一层卷积层计算之后,激活函数之前用于对计算后的数据进行标准化,输出后再作为激励层的输入,可达到调整激励函数偏导的作用。并且 Batch Normalization 层也含有训练参数,需要参与网络训练!
7. dropout 层
通过使用dropout层,我们可以避免过拟合,并增强模型的泛化能力。dropout层在模型训练过程中通过使用一个丢弃概率p,使得该层(layer)的神经元在每次迭代训练时会随机有 p概率 的可能性被丢弃(失活),从而不参与训练。这样,每次训练都随机让一定神经元停止参与运算,简单的操作让我们由一个模型演变成多个模型,形成一个多模型投票机制,使得模型稳定性和鲁棒性被大大提高了。
注意:在模型测试和应用过程中是要取消dropout层的,dropout只在训练过程中起到作用,对模型参数训练避免过拟合,提高泛化能力!

三.卷积神经网络实践
此处实践以 手写数字识别问题 为例,使用Pytorch框架实现。训练数据集为 60000 * 1 * 28 * 28 (N * C * H * W),batch_size = 64,使用 CrossEntropyLoss 作为模型损失(自动包含softmax分类计算),并使用随机梯度下降SGD算法进行优化。Pytorch相关的卷积层函数为 Conv1d、Conv2d、Conv3d 等,可在官网查看文档。

import torch
import torch.nn.functional as F
from torch import optim
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
# 一.基础CNN网络(LeNet)
# 2. 定义CNN网络
class CnnNet(torch.nn.Module):
def __init__(self):
super(CnnNet, self).__init__()
#torch.nn.Conv2d:二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)
# n_channels(int) – 输入信号的通道
# out_channels(int) – 卷积产生的通道
# kerner_size(int or tuple) - 卷积核的尺寸
# stride(int or tuple, optional) - 卷积步长
# padding(int or tuple, optional) - 输入的每一条边补充0的层数
# bias(bool, optional) - 如果bias=True,添加偏置。默认True bais(H`,W) + sum(内积)
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5) #(batch * 1 * 28 * 28)-> (batch * 10 * 24 * 24)
#pooling -> (batch * 10 * 12 * 12)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5) #(batch * 20 * 12 * 12)-> (batch * 20 * 8 * 8)
#pooling -> (batch * 20 * 4 * 4)
self.pooling = torch.nn.MaxPool2d(2)
#Liner (batch * 320)
self.liner1 = torch.nn.Linear(320,80)
# Liner (batch * 80)
self.liner2 = torch.nn.Linear(80,10)
def forward(self,x):
batch = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch,-1) #flatten
x = F.relu(self.liner1(x))
#最后一层线性层不需要激活,交由CrossEntory处理
return self.liner2(x)
# 1.准备数据
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
#读取训练集合 60000 * 1 * 28 * 28 (N * C * H * W)
train_datasets = datasets.MNIST(root='../dataset/mnist/',train=True,transform=transform,download=True)
#训练数据加载器 64 * 1 * 28 * 28
train_loader = DataLoader(dataset=train_datasets,batch_size=batch_size,shuffle=True)
test_datasets = datasets.MNIST(root='../dataset/mnist/',train=False,transform=transform,download=True)
test_loader = DataLoader(dataset=test_datasets,batch_size=batch_size,shuffle=False)
# 3.准备损失和优化
model = CnnNet()
criterion = torch.nn.CrossEntropyLoss()
optimier = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
# 4.训练数据
def trainDatasets(epoch):
running_loss = 0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target = data
optimier.zero_grad()
outputs = model.forward(inputs)
loss = criterion(outputs,target)
loss.backward()
optimier.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
# 5.测试数据
def testDatasets():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
test_input, labels = data
test_output = model.forward(test_input)
_, predicted = torch.max(F.softmax(test_output.data, dim=1), dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total,correct,total))
if __name__ == '__main__':
for epoch in range(10):
trainDatasets(epoch)
testDatasets()
torch.save(model.state_dict(),"cnn.pkl") #保存网络参数四.卷积神经网络进阶
1.GooleNet
GooleNet Inception实现
1.什么是Inception:Inception就是把多个卷积或池化操作,放在一起组装成一个网络模块,设计神经网络时以模块为单位去组装整个网络结构。
2.Inception内容:包含两个方面,1*1卷积的使用 + 多尺寸卷积信息聚合拼接
3.多尺寸卷积聚合好处、作用:
(1)采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合。使得信息更加丰富,网络的表达能力更强
(2)一个Inception模块中并列提供多种卷积核的操作,网络在训练的过程中通过调节参数自己去选择具体使用哪一个,侧重使用哪一个。更加灵活
(3)利用稀疏矩阵分解成多个密集子矩阵计算的原理来加快收敛速度。
4.1*1卷积使用的好处、作用:
(1)1*1的卷积核可以在不改变输入大小的情况下,对数据进行降维,大大减少了运算量
(2)1*1卷积的运算量降低 可以使得网络添加更多的卷积层,同时1*1同时卷积引入了激励函数,能提取到更丰富的特征
5.改进:使用更多的3*3卷积来代替5*5卷积。原因是,每两个3*3卷积的结果 = 一个5*5卷积的结果,但是两个3*3卷积的叠加比一个5*5提取信息更丰富


# GooleNet Inception实现
class GooleInspection(torch.nn.Module):
def __init__(self,in_channels):
super(GooleInspection, self).__init__()
#每一分支必须 维持 h w 不变 , 通道channel可以改变
#分支一
self.branch1_pool = torch.nn.AvgPool2d(kernel_size=3,stride=1,padding=1)#(batch,in_channels,h,w) =>(batch,in_channels,h+2-3+1,w+2-3+1)
self.branch1_1x1 = torch.nn.Conv2d(in_channels,24,kernel_size=1) #(batch,in_channels,h,w) => (batch,24,h,w)
#分支2
self.branch2_1x1 = torch.nn.Conv2d(in_channels,16,kernel_size=1) #(batch,in_channels,h,w) => (batch,16,h,w)
#分支3
self.branch3_1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) # (batch,in_channels,h,w) => (batch,16,h,w)
self.branch3_5x5 = torch.nn.Conv2d(16, 24, kernel_size=5,padding=2) # (batch,16,h,w) => (batch,24,h,w)
#分支4
self.branch4_1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) # (batch,in_channels,h,w) => (batch,16,h,w)
self.branch4_3x3_1 = torch.nn.Conv2d(16, 24, kernel_size=3,padding=1) # (batch,16,h,w) => (batch,24,h,w)
self.branch4_3x3_2 = torch.nn.Conv2d(24, 24, kernel_size=3,padding=1) # (batch,24,h,w) => (batch,24,h,w)
def forward(self,x):
res_branch1 = self.branch1_1x1(self.branch1_pool(x))
res_branch2 = self.branch2_1x1(x)
res_branch3 = self.branch3_5x5(self.branch3_1x1(x))
res_branch4 = self.branch4_3x3_2(self.branch4_3x3_1(self.branch4_1x1(x)))
outputs = [res_branch1,res_branch2,res_branch3,res_branch4]
#cat:在给定维度上对输入的张量序列seq 进行连接操作。
# inputs (sequence of Tensors) – 可以是任意相同Tensor 类型的python 序列
# dimension (int, optional) – 沿着此维连接张量序列。
return torch.cat(outputs,dim=1) #合并res,Concatenate (batch,88,h,w)
class GooleNet(torch.nn.Module):
def __init__(self,init_channels):
super(GooleNet, self).__init__()
self.conv1 = torch.nn.Conv2d(init_channels,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(88,20,kernel_size=5)
self.incep1 = GooleInspection(in_channels=10)
self.incep2 = GooleInspection(in_channels=20)
self.pooling = torch.nn.MaxPool2d(2)
self.linear = torch.nn.Linear(1408,10)
def forward(self,x):
in_size = x.size(0) #batch_size
x = F.relu(self.pooling(self.conv1(x))) #(batch,channel,h,w) => (batch,10,(h-4)/2,(w-4)/2)
x = self.incep1(x) #(batch,10,(h-4)/2,(w-4)/2) => (batch,88,(h-4)/2,(w-4)/2)
x = F.relu(self.pooling(self.conv2(x))) #(batch,88,(h-4)/2,(w-4)/2) => (batch,20,((h-4)/2-4)/2,((w-4)/2-4)/2)
x = self.incep2(x) #(batch,20,((h-4)/2-4)/2,((w-4)/2-4)/2) => (batch,88,((h-4)/2-4)/2,((w-4)/2-4)/2)
x = x.view(in_size,-1) #(batch,1408)
x = self.linear(x)
return x2.ResidualNet
Residual Net ---- 解决深层网络梯度消失问题
1.现象:若干个梯度<1的相乘,导致梯度不断变小->0,使得w不再更新(梯度消失)
2.解决方法:
(1)锁层:每一层单独训练,锁住参数(不推荐,太麻烦)
(2)Residual Net:H(x) = F(x) + x,添加跳连接操作,使用这样的块训练(跳连接块),x提供的求导1 解决了梯度->0的缺点(梯度->1)

#Residual Net
class ResidualBlock(torch.nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.channels = channels
#卷积操作不改变 输入数据的 尺寸
self.conv1 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
#先求和,后激活
return F.relu(y + x)
class ResidualNet(torch.nn.Module):
def __init__(self):
super(ResidualNet, self).__init__()
self.conv1 = torch.nn.Conv2d(1,16,kernel_size=5)
self.conv2 = torch.nn.Conv2d(16,32,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.linear = torch.nn.Linear(512,10)
def forward(self,x):
in_size = x.size(0)
x = F.relu(self.conv1(x)) #(batch,1,28,28) => (batch,16,24,24)
x = self.pooling(x) #(batch,16,24,24) => (batch,16,12,12)
x = self.rblock1(x) #(batch,16,12,12) => (batch,16,12,12)
x = F.relu(self.conv2(x)) # (batch,16,12,12) => (batch,32,8,8)
x = self.pooling(x) # (batch,32,8,8) => (batch,32,4,4)
x = self.rblock2(x) # (batch,32,4,4) => (batch,32,4,4)
x = x.view(in_size,-1) #(batch,512)
return self.linear(x)